Structural Equation Modelling
Nils Holmberg
210401
SEM using R package “lavaan”
The lavaan (latent variable analysis) package is developed to provide useRs, researchers and teachers a free open-source, but commercial-quality package for latent variable modeling. You can use lavaan to estimate a large variety of multivariate statistical models, including path analysis, confirmatory factor analysis, structural equation modeling and growth curve models.
#install.packages("lavaan", dependencies=TRUE, lib="~/lib/r-cran")
#install.packages("lavaan", dependencies=TRUE, lib="C:/Program Files/R/lib")
library(lavaan)Revisit theoretical model
We test whether animosity towards Germany and ethnocentrism more generally, predict consumer attitudes (ATT) towards German automotive brand SMART. We also investigate whether higher levels of ATT significantly improve perceptions of fit for a hypothetical sponsorship between SMART and the England international soccer team.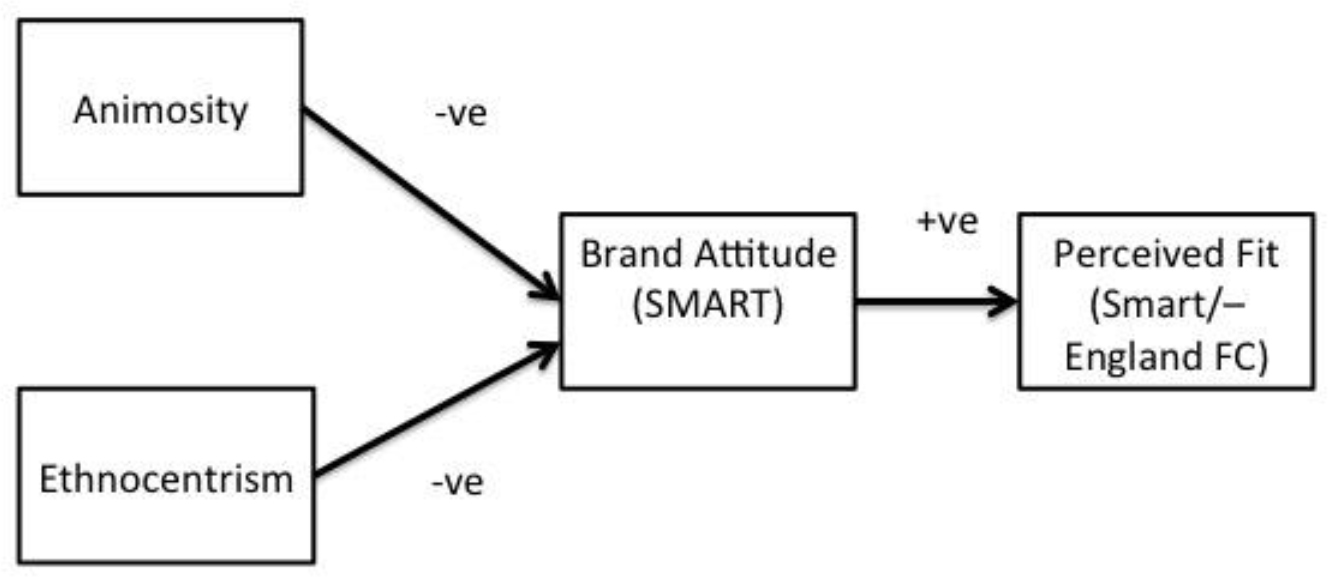
Theoretical model
Step 1: Confirmatory Factor Analysis
Let’s build out the measurement model to include not only the two exogeneous variables discussed in the previous examples, but also the two endogeneous (dependent) variables stated in the theoretical model.
#install.packages("lavaan", dependencies=TRUE, lib="C:/Program Files/R/lib")
#install.packages("lavaan", dependencies=TRUE, lib="~/lib/r-cran")
library(lavaan)
#specify model, latent variables
iss.model <- '
# measurement model
animosity =~ ANI1 + ANI2 + ANI3 + ANI4
ethnocentrism =~ ETHNO1 + ETHNO2 + ETHNO3
brand_attitude =~ AT1 + AT2
brand_fit =~ FIT1 + FIT2
'
#fit model
fit <- cfa(iss.model, data=dfs)
#check standardized factor loadings (check significance values <0.05)
#Standardized Regression Weights, all factor loadings are high (i.e., >.70)
#inspect(fit, what="std")
#check if model fits data, commonly accepted thresholds
#Chi-square: p > 0.05
#CFI: > 0.90
#TLI: > 0.95 (0.90)
#RMSEA: < 0.10
summary(fit, fit.measures=TRUE, standardized=TRUE)## lavaan 0.6-8 ended normally after 45 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 28
##
## Number of observations 123
##
## Model Test User Model:
##
## Test statistic 52.674
## Degrees of freedom 38
## P-value (Chi-square) 0.057
##
## Model Test Baseline Model:
##
## Test statistic 988.835
## Degrees of freedom 55
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.984
## Tucker-Lewis Index (TLI) 0.977
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -1871.966
## Loglikelihood unrestricted model (H1) -1845.629
##
## Akaike (AIC) 3799.932
## Bayesian (BIC) 3878.673
## Sample-size adjusted Bayesian (BIC) 3790.139
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.056
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.090
## P-value RMSEA <= 0.05 0.368
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.047
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## animosity =~
## ANI1 1.000 1.184 0.848
## ANI2 1.035 0.074 13.962 0.000 1.226 0.936
## ANI3 1.013 0.078 13.044 0.000 1.199 0.893
## ANI4 0.829 0.090 9.260 0.000 0.982 0.720
## ethnocentrism =~
## ETHNO1 1.000 1.144 0.867
## ETHNO2 1.174 0.098 12.034 0.000 1.343 0.838
## ETHNO3 1.129 0.082 13.856 0.000 1.291 0.942
## brand_attitude =~
## AT1 1.000 1.110 0.907
## AT2 1.161 0.178 6.522 0.000 1.289 0.998
## brand_fit =~
## FIT1 1.000 1.019 0.739
## FIT2 1.324 0.392 3.376 0.001 1.350 0.938
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## animosity ~~
## ethnocentrism 0.412 0.140 2.954 0.003 0.304 0.304
## brand_attitude -0.110 0.124 -0.885 0.376 -0.084 -0.084
## brand_fit 0.059 0.120 0.488 0.626 0.048 0.048
## ethnocentrism ~~
## brand_attitude 0.035 0.119 0.295 0.768 0.028 0.028
## brand_fit -0.122 0.120 -1.020 0.308 -0.105 -0.105
## brand_attitude ~~
## brand_fit 0.294 0.141 2.083 0.037 0.260 0.260
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .ANI1 0.549 0.086 6.363 0.000 0.549 0.281
## .ANI2 0.212 0.056 3.778 0.000 0.212 0.124
## .ANI3 0.365 0.067 5.417 0.000 0.365 0.203
## .ANI4 0.895 0.123 7.251 0.000 0.895 0.481
## .ETHNO1 0.431 0.079 5.487 0.000 0.431 0.248
## .ETHNO2 0.766 0.125 6.135 0.000 0.766 0.298
## .ETHNO3 0.213 0.076 2.794 0.005 0.213 0.113
## .AT1 0.264 0.185 1.431 0.153 0.264 0.177
## .AT2 0.006 0.245 0.025 0.980 0.006 0.004
## .FIT1 0.865 0.315 2.743 0.006 0.865 0.454
## .FIT2 0.249 0.519 0.480 0.631 0.249 0.120
## animosity 1.402 0.244 5.746 0.000 1.000 1.000
## ethnocentrism 1.308 0.222 5.890 0.000 1.000 1.000
## brand_attitude 1.231 0.261 4.715 0.000 1.000 1.000
## brand_fit 1.039 0.366 2.838 0.005 1.000 1.000Step 2: Structural Equation Modelling
If the preceeding CFA produced acceptable results, then continue expanding the model with two directional regression analyses, i.e. the structural model, again according to the theoretical model.
#specify model, latent variables, regressions, residuals, covariances
iss.model <- '
# measurement model
animosity =~ ANI1 + ANI2 + ANI3 + ANI4
ethnocentrism =~ ETHNO1 + ETHNO2 + ETHNO3
brand_attitude =~ AT1 + AT2
brand_fit =~ FIT1 + FIT2
# structured model, directional regressions
brand_attitude ~ animosity + ethnocentrism
brand_fit ~ brand_attitude
# residual correlations, endogeneous
#
# covariances, exogeneous variables
#animosity ~~ ethnocentrism
'
#fit model
fit <- sem(iss.model, data=dfs)
#check if model fits data, commonly accepted thresholds
#Chi-square: p > 0.05
#CFI: > 0.90
#TLI: > 0.95 (0.90)
#RMSEA: < 0.10
summary(fit, fit.measures=TRUE, rsquare=TRUE, standardized=TRUE)## lavaan 0.6-8 ended normally after 45 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 26
##
## Number of observations 123
##
## Model Test User Model:
##
## Test statistic 55.317
## Degrees of freedom 40
## P-value (Chi-square) 0.054
##
## Model Test Baseline Model:
##
## Test statistic 988.835
## Degrees of freedom 55
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.984
## Tucker-Lewis Index (TLI) 0.977
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -1873.288
## Loglikelihood unrestricted model (H1) -1845.629
##
## Akaike (AIC) 3798.576
## Bayesian (BIC) 3871.693
## Sample-size adjusted Bayesian (BIC) 3789.482
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.056
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.089
## P-value RMSEA <= 0.05 0.371
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.056
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## animosity =~
## ANI1 1.000 1.184 0.848
## ANI2 1.035 0.074 13.970 0.000 1.226 0.936
## ANI3 1.012 0.078 13.044 0.000 1.199 0.893
## ANI4 0.829 0.090 9.255 0.000 0.982 0.720
## ethnocentrism =~
## ETHNO1 1.000 1.145 0.869
## ETHNO2 1.173 0.097 12.068 0.000 1.344 0.839
## ETHNO3 1.125 0.081 13.850 0.000 1.289 0.940
## brand_attitude =~
## AT1 1.000 1.109 0.907
## AT2 1.163 0.187 6.218 0.000 1.290 0.999
## brand_fit =~
## FIT1 1.000 1.031 0.747
## FIT2 1.295 0.436 2.969 0.003 1.335 0.927
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## brand_attitude ~
## animosity -0.095 0.093 -1.021 0.307 -0.102 -0.102
## ethnocentrism 0.057 0.096 0.592 0.554 0.059 0.059
## brand_fit ~
## brand_attitude 0.243 0.111 2.200 0.028 0.262 0.262
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## animosity ~~
## ethnocentrism 0.415 0.140 2.968 0.003 0.306 0.306
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .ANI1 0.549 0.086 6.361 0.000 0.549 0.281
## .ANI2 0.212 0.056 3.766 0.000 0.212 0.124
## .ANI3 0.366 0.068 5.421 0.000 0.366 0.203
## .ANI4 0.896 0.124 7.252 0.000 0.896 0.482
## .ETHNO1 0.427 0.078 5.441 0.000 0.427 0.245
## .ETHNO2 0.763 0.125 6.114 0.000 0.763 0.297
## .ETHNO3 0.219 0.076 2.870 0.004 0.219 0.117
## .AT1 0.266 0.194 1.372 0.170 0.266 0.178
## .AT2 0.004 0.258 0.014 0.989 0.004 0.002
## .FIT1 0.842 0.363 2.315 0.021 0.842 0.442
## .FIT2 0.290 0.583 0.497 0.619 0.290 0.140
## animosity 1.403 0.244 5.747 0.000 1.000 1.000
## ethnocentrism 1.312 0.222 5.904 0.000 1.000 1.000
## .brand_attitude 1.217 0.264 4.616 0.000 0.990 0.990
## .brand_fit 0.990 0.370 2.679 0.007 0.931 0.931
##
## R-Square:
## Estimate
## ANI1 0.719
## ANI2 0.876
## ANI3 0.797
## ANI4 0.518
## ETHNO1 0.755
## ETHNO2 0.703
## ETHNO3 0.883
## AT1 0.822
## AT2 0.998
## FIT1 0.558
## FIT2 0.860
## brand_attitude 0.010
## brand_fit 0.069Interpret results
Stated in the form of three directional hypotheses, the following predicted relationships are tested:
- H1a: Higher animosity towards Germany leads to a lower attitude towards SMART.
- H1b: Higher ethnocentrism leads to a lower attitude towards SMART car brand.
- H1c: A higher attitude towards SMART leads to a more favourable perception of its fit with the England soccer team as its primary sponsor.
Wrap-up
- what is sem, concepts, short intro, confirmatory framework
- when do we use sem, social science, survey research, tpb
- what are the advantages of sem, multiple regression
- how can we work with sem, spss, r
#